-
데이터베이스 커서 트리거 전체 텍스트 검색(2020.06.12)데이터베이스 2020. 6. 12. 13:45
커서
어려운 부분
행의 집합을 다루는데 제공해주는 편리한 기능
- SQL Server의 성능을 느리게 하는 요인이 될 수 있으므로, 특별한 경우가 아니라면 되도록 사용하지 않을 것을 권항함
- 파일처리시의 파일 포인터와 비슷한 작동을 함.
마치 반복문에서의 배열과 같이 배열의 인덱스에 접근하는 i나 j 같은 역할을 한다. 예전에는 많이 썼었다.

커서의 선언(DECLARE) -> 커서 열기(OPEN) ->
커서에서 데이터 가져오기(FETCH) -> 데이터 처리 -> (WHILE문으로 모든 행이 처리될 때까지 반복)
커서 닫기(CLOSE) -> 커서의 해제(DEALLOCATE)

빅데이터 데이터마이닝을 위한 데이터를 강사님께서 주신 자료로 진행했다.

구분자는 ' | ' 이다.

C 폴더 안에 Temp 라는 폴더를 만들고 데이터를 집어넣는다.

SSMS 에서 열기
sql 내부에 있는 CREATE DATABASE 문과 CREATE TABLE명령을 실행 시키면

데이터베이스와 테이블이 생성된다.
INSERT 문 사용해서 데이터를 넣었다.
커서의 기본 이용


커서를 쓰는 이유는 반복문을 사용해서 위 리스트를 읽을 때 한줄 한줄 처리하고 싶을 때 유용하다.
DECLARE cur CURSOR FOR --이게 중요 cursor를 뭘로 만들지 정한다.
SELECT name, birthYear, height FROM userTblOPEN cur; --커서 열기
FETCH NEXT FROM cur INTO @name, @byear, @height --여기 순서 맞춰야 한다,위의 커서를 두개를 줄 수도 있다. 순서도 맞춰야 한다.
FETCH NEXT FROM cur INTO @byear
다음 커서를 가리킨다.
트리거
트리거는 제약조건과 더불어서 데이터의 무결성을 위한 또다른 기능
- DML 트리거, DDL 트리거, LOGON 트리거 세 가지가 있음
- 테이블 또는 뷰에 부착(Attach)되는 프로그램 코드
- 저장 프로시저와 비슷하게 작동하지만 직접 실행시킬 수는 없고 오직 해당 테이블이나 뷰에 이벤트(입력, 수정,삭제)가 발생 할 경우에만 실행됨
- 저장프로시저와 달리 매개변수나 리턴값을 사용할 수 없음
# DDL 트리거는 2005 부터 LOGON 트리거는 2008부터 지원함
CREATE TRIGGER testTrg --트리거 이름
ON testTbl -- 트리거를 부착할 테이블
AFTER DELETE, UPDATE -- 삭제, 수정후에 작동하도록 지정
AS
PRINT('트리거가 작동했습니다.') --트리거 실행시 작동되는 코드들
-- 삭제나 수정이 발생 되면 '트리거가 작동했습니다.' 출력
AFTER 트리거
삽입, 수정, 삭제 등의 작업이 있어났을 때 작동하는 트리거를 말하며, 이름이 뜻하는 것처럼, 해당 작업 후에 작동한다.
INSTEAD OF 트리거
위와 반대로 이벤트가 발생하기 전에 작동하는 트리거다.

트리거 -> 새 트리거

새 쿼리
UPDATE userTbl
SET addr='제주'
WHERE userID='EJW'위와 같이 실행 하면 제주로 수정하기 전, 이전데이터를 backup_userTbl에 저장하고, trgerType은 수정으로 바뀐다. 이런 히스토리 테이블을 만들면 잘못 수정되도, 다시 예전 데이터로 돌릴 수 있다. 마찬가지로 IF와 대응하는 ELSE를 사용해서 삭제를 사용할 때도 조건문 안에 적어주면 된다,
DELETE userTbl
WHERE userID = 'JYP' 는 자식테이블로 못지운다.buyTbl과의 연결을 끊어야한다.

위와 같이 계단식 배열로 바꾸면 삭제가 된다.. 만약 'JYP'를 삭제한다면 buyTbl의 조용필 행 또한 삭제되고, userTbl의 삭제한 열은 backup_userTbl 저장된다.
전체 텍스트 검색
전체 텍스트 검색 서비스 는 SQL Server 추가 기능이다.
긴 문장으로 구성된 열의 내용을 검색할 때 전체 텍스트 인덱스를 사용해서 빠른 시간에 검색하는것.
기존 인덱스가 중간에 들어있는 글자로 검색할 때는 인덱스를 사용하지 못하는 문제점을 해결해 줌
'SQL Full -text Filter Daemon Launcher'라는 서비스가 등록되고 가동되어야 한다.
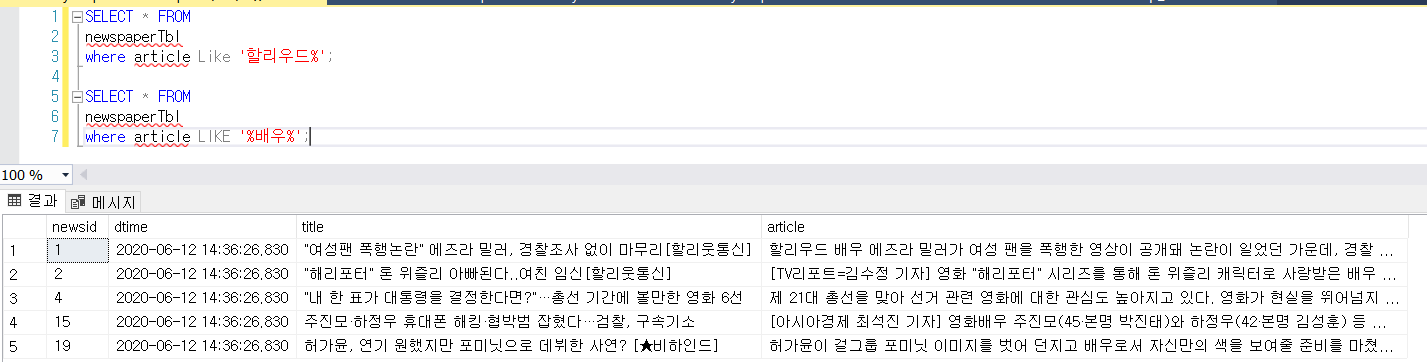
이렇게 찾으면 데이터가 많아지면 성능이 엄청나게 떨어진다. 그래서 만든게 풀 텍스트 서치 이다.
아래와 같이 Full-text filter daemon launcher 가 실행중이어야 한다.

따로 인덱스를 만들어야 한다.
CREATE TABLE newspaperTBL (
newsid INT NOT NULL IDENTITY primary key,
dtime DATETIME NULL,
title NVARCHAR(255) NULL,
article NVARCHAR(MAX)
);전체 텍스트 인덱스는 테이블 당 하나만 생성할 수 있다.
전체 텍스트인덱스에 데이터를 추가하는 채우기(Population)는 일정 예약이나 특별한 요청에 의해서 수행되거나, 새로운데이터를 INSERT할 때 자동으로 수행되게 할 수도 있다.
대ㅔ이터가 많이 들어가겠다 싶은 것들에 생성한다,
전체 텍스트 인덱스를 생성할 테이블에는 Primary Key나 Unique Key가 있어야 한다.
전체 텍스트 카탈로그 ㅣ 전체 텍스트가 저장되는 가상의 공간
| 전체 텍스트 인덱스가 생성되기 전에 생성해 놓아야 함
SQL Server2008부터는 전체 텍스트 인덱스가 데이터베이스 내부에 저장되기 때문에 전체 텍스트 카탈로그의 의미가 별로 중요치 않다.
풀 텍스트 인덱스 채우기
전체 텍스트 인덱스를 생성하고 관리하는 것을 말함
채우기 방법
- 전체 채우기 : 처음 전체 텍스트 인덱스를 생성할 때 지정한 열의 모든 데이터 행에 대해서 인덱스를 생성하는 것을 말한다.
- 변경 내용 추적 기반 채우기 : 전체 채우기를 수행한 이후에, 변경된 내용을 채우는 것을 말한다,
- 증분 타임스탬프 기반 채우기 : 증분 채우기는 마지막 채우기 후 추가, 삭제, 수정된 행에 대해서 전체 텍스트 인덱스를 업데이트한다.
중지 단어 및 중지 목록

별 의미가 없느느 1,3,6,7 번을 제외시키는 것이다.


저 인덱스로 데이터가 많아지면 많아질수록 빛을 발한다.

빠르답니다.
OR , AND 사용 가능





다음 다음 마침

인덱스 생성 완료

인덱스 프라이머리 키에 붙어있는 클러스터형 인덱스는
'데이터베이스' 카테고리의 다른 글
데이터베이스 인덱스, 트랜잭션, 저장 프로시저(2020.06.11) (0) 2020.06.11 데이터베이스 테이블과 뷰(2020.06.10) (0) 2020.06.10 데이터베이스 조인 조건 반복 동적(2020.06.10) (0) 2020.06.10 데이터베이스 Transact-SQL 기본, 고급(2020.06.09) (0) 2020.06.09 데이터베이스 Transact-SQL 기본 (2020.06.08) (0) 2020.06.08