-
데이터베이스 인덱스, 트랜잭션, 저장 프로시저(2020.06.11)데이터베이스 2020. 6. 11. 11:05
인덱스 : 책의 뒷부분에 있는 색인(또는 찾아보기)와 비슷한 개념
작은 데이터에는 없어도 별 차이가 없지만, 대량의 데이터에는 인덱스가 있어야만 데이터를 빠른 시간에 검색할 수 있음
장점 : 검색은 속도가 무척 빨라질 수 있다.
그 결과 시스템의 부하가 줄어들어서, 결국 시스템 전체의 성능이 향상된다.
단점 : 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간이 필요해 진다. (대략 데이터베이스의 10%내외의 공간이 추가로 필요하다.)
인덱스를 생성하는데 시간이 많이 소요될 수 있다.
데이터의 변경 작업 (Insert, Update, Delete)이 자주 일어날 경우에는 성능이 많이 나빠질 수도 있다.
SELECT 할땐 좋다,
종류
클러스터형 인덱스 -> 영어사전과 비슷한 개념 A~Z 트리구조로 빨리 찾을수 있게 되있다.
비클러스터형 인덱스 ->일반 책의 '찾아보기'와 비슷한 개념
특징
클러스터형 인덱스는 테이블당 1개만 생성
비클러스터형 인덱스는 테이블당 여러 개 생성
넌클러스터형
기본 키 2 4 3 1 순으로 정렬됨
ID (정렬)
1 홍길동
2 김범수
3 성시경
4 바비킴
클러스터형 인덱스
새 테이블 생성으로 기본키가 없는 테이블을 생성 했을 때, 인덱스고 제약조건이고 아무것도 없다.
하지만 기본키를 지정하면 클러스터형 인덱스가 자동으로 생성된다. 키 제거를 하고 새로고침하면
키 없어지고 인덱스도 없어진다.
넌 클러스터형 인덱스 생성

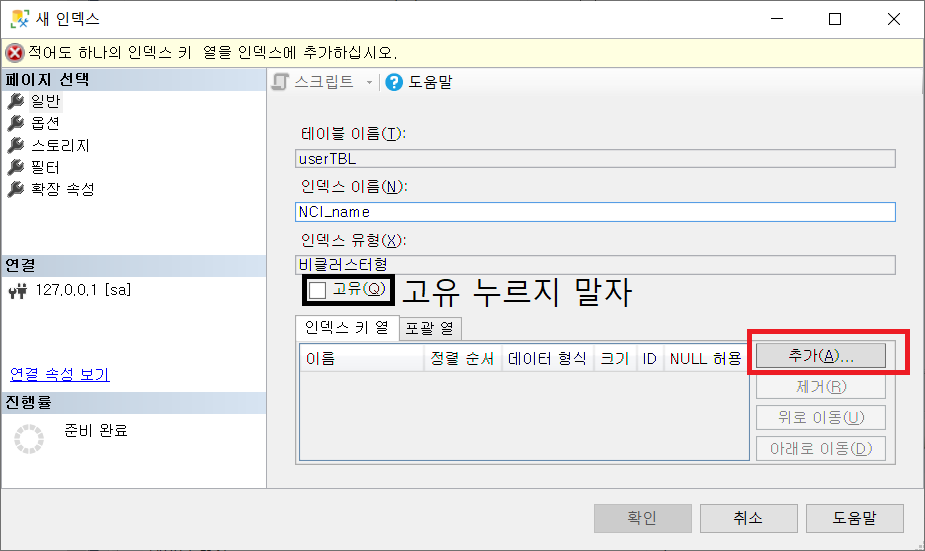
EXEC sp_helpindex userTBL; 명령으로 확인 가능
트리 형태 구조 넌클러스터

클러스터 인덱스의 특징
- 클러스터형 인덱스의 생성시에는 데이터페이지 전체를 다시 정렬하게 된다.
- 클러스터형 인덱스를 생성은 심각한 시스템 부하를 줄 수 있다.
- 클러스터형 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터이다.
- 비 클러스터형 보다 검색속도는 더 빠르다. 하지만, 데이터의 입력/수정/삭제는 더 느리다.
- 클러스터형 인덱스는 성능이 좋지만, 테이블에 한 개 밖에 생성하지 못한다. 그러므로, 어느 열에 클러스터형 인덱스를 생성하느냐에 따라서 시스템의 성능이 달라질 수 있다.
인덱스를 생성해야 하는 경우와 그렇지 않은 경우
- 인덱스는 열 단위에 생성된다.
- where 절에서 사용되는 컬럼을 인덱스로 만든다.
- where 절에 사용되더라도 자주 사용해야 가치가 있다.
- 데이터의 중복도가 높은 열은 인덱스를 만들어도 별 효용이 없다.
- 외래키가 사용되는 열에는 인덱스를 되도록 생성해 주는 것이 좋다.
- JOIN에 자주 사용되는 열에는 인덱스를 생성해 주는 것이 좋다.
- INSERT/UPDATE/DELETE 가 얼마나 자주 일어나는 지를 고려한다.
- 클러스터형 인덱스는 하나만 생성할 수 있다.
- 클러스터형 인덱스가 테이블에 아예 없는 것이 좋은 경우도 있다.
- 사용하지 않는 인덱스는 제거하자.
- 계산열에도 인덱스를 활용 할 수 있다.
트랜잭션
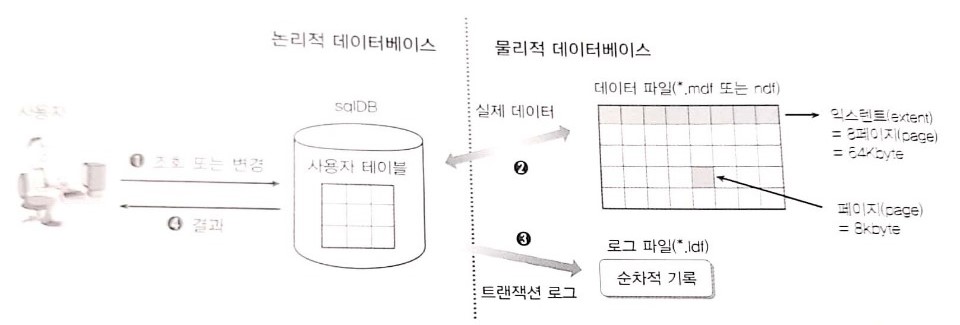
데이터베이스의 물리적 실체
- 데이터베이스는 물리적 파일임
- 기본적으로*mdf와 .ldf 두파일이 생김
데이터 파일
.mdf 또는 .ndf 로 생성됨
이파일에는 데이터 베이스 개체와 그행 데이터가 저장됨
SQL문이 동작하는 데이터 베이스의 간단한 구조도
- SELECT 문 1->2->4
- UPDATE 문 1->3->2->4
트랜잭션 개념
- 하나의 논리적 작업단위로 수행되는 일련의 작업
- SQL문 (SELECT/INSERT/UPDATE/DELETE))의 묶음
- 한 단위의 트랜잭션은 모두 처리되거나 모두 처리 되지 않도록 DBMS가 관리해 준다.
모두 처리되는 것을 COMMIT 처리되지 않도록 되돌리는 것을 ROLLBACK이라고 한다.
구문 형식
BEGIN TRANSACTION (또는 BEGIN TRAN)
SQL문장들
COMMIT TRANSACTION (또는 COMMIT TRAN 또는 COMMIT WORK)

SET IMPLICIT_TRANSACTIONS 에 암시적 트랜잭션을 체크한다. 저걸 체크하면 Auto Commit. 체크 해제하면 가속 데이터 베이스 복구라고 2019부터 새로운 기능인데 즉시 트랜잭션 롤백을 지원한다. 커밋해도 롤백이 적용된다.
UPDATE buyTBL
SET price = 50,
amount = 4
WHERE num = 10;
1개 행이 적용됨
BEGIN TRAN
SELECT * FROM buyTBL
WHERE num = 10;
UPDATE buyTBL
SET price = 50,
amount = 4
WHERE num = 10;
COMMIT;
ROLLBACK;
위와 같이 넘버 10번에 대한 값을 줬는데 다시 되돌려야 할 때 BEGIN TRAN; 을 먼저 실행한다. 그리고 안의 내용 실행 하고 실행하면 수정된다. 아까로 돌아가려면 ROLLBACK을 실행하면 변경전 사항으로 들어간다. 다시 BEGIN TRAN을 하고 안의 바꿀 내용 실행, 변경사항이 적용 된다. COMMIT을 실행하면 변경사항이 완전히 적용된다.
트랜잭션의 특성
- 원자성 : 트랜잭션은 분리할 수 없는 하나의 단위이다.
- 일관성 : 트랜잭션에서 사용되는 모든 데이터는 일관되어야 한다.
- 격리성 : 현재 트랜잭션이 접근하고 있는 데이터는 다른 트랜잭션에서 격리되어야 한다는 것을 의미한다.
- 영속성 : 트랜잭션이 정상적으로 종료된다면 그 결과는 시스템 오류가 발생하더라도 시스템에 영구적으로 적용된다.
BEGIN 한다음 커밋 OR 롤백
저장 프로시저
저장 프로시저 란 SQL SERVER에서 제공되는 프로그래밍 기능
- 저장 프로시저는 한마디로 쿼리문의 집합으로 어떠한 동작을 일괄 처리하기 위한 용도로 사용

매개변수 주기


매개변수 1개


매개변수 2개

값을 미리 주고 결과만 보기

리턴 값 받아서 활용하기


프로시저 안에 조건문 달기
이승기와 바비킴에 대한 나이의 결과 출력

점점 저장 프로시저를 쓰지 않는다. DATABASE에서 저장프로시저 처리한 결과를 C#은 처리만 했는데, 저장 프로시저엔 단점이 있는데, 비즈니스 로직이란 것이 있는데, 화면을 꾸미는 UI의 기능을 처리할 때, C#에서만 처리하면 좋은데, 저장 프로시저를 사용하면 데이터베이스까지 손을 봐야 한다. 따라서 개발자들의 편의를 위해서 거의 안 쓰는 추세로 가고 있다. 그러면 C#개발자가 할일이 많아지고 C#의 비즈니스 로직이 커진다.
첫 번째 실행 시 메모리에 올라가게 되고, 두 번째 실행부터 실행속도가 캐시에 이미 있으므로 실행속도가 빠르다. 요즘에는 어차피 빠르기 때문에 저장 프로시저 없이 C#에 몰빵한다.
저장 프로시저
- SQL Server의 성능을 향상 시킬 수 있다.
- 모듈식 프로그래밍이 가능하다.
- 보안을 강화할 수 있다.
- 네트워크 전송량을 감소시킨다.
많이 쓸 것 같지만 비즈니스 로직을 두군데 관리해야 하는 단점에 잘 안쓴다.
시스템 저장 프로시저
- 시스템을 관리하기 위해서 SQL Server가 제공해주는 저장 프로시저로, SQL Server와 관리와 관련된 작업을 위해서 사용한다.
사용자 정의 함수
저장프로시저와 조금 비슷해 보이지만, 일반적인 프로그래밍 언어에서 사용되는 함수와 같이 복잡한 프로그래밍이 가능
함수는 RETRUN 문에 의해서 특정 값을 되돌려 줌
* 저장 프로시저는 'EXEC' 에 의해서 실행되지만 함수는 주로 'SELECT' 문에 포함되어 실행됨 (예외도 있음)
이것도 C#에 다박아서 쓰는 것을 선호한다.
CREATE FUNCTION ufn_getAge(@byear INT)
RETRUNS INT
AS
BEGIN
SQL문
END
GO
시스템 저장 함수 

오늘거 던짐
사용자 정의 테이블 반환 함수
테이블을 반환해준다.
CREATE FUNCTION 함수이름 (매개변수)
RETURNS TABLE
AS
RETRUN (
단일 테이블
)



180보다 큰 사람이 있는 테이블 반환
스칼라 함수와 테이블을 반환해주는 함수
다중 문 테이블 반환 함수도 있다 . 리턴을 한꺼번에 여러개.
사용자 정의 함수의 제약 사항
TRY CATCH 문 사용 할 수 없다.
사용자 정의함수 내부에 CREATE/ ALTER / DROP문을 사용하지 못한다.
오류가 발생하면 즉시 함수의 실행이 멈추고 값을 반환하지 않는다.
주로 스칼라 변환함수 값을 처리할 때 많이 사용한다.
저장 프로시저는 점점 사용하는 빈도수가 줄어들고 있고, 거기엔 비즈니스 로직들이 많이 들어가기때문에 데이터베이스와 c# 두군데서 관리해야 해서 줄어든다. 하지만 빠르기 때문에 아직도 쓰는 회사들이 있다.
'데이터베이스' 카테고리의 다른 글
데이터베이스 커서 트리거 전체 텍스트 검색(2020.06.12) (0) 2020.06.12 데이터베이스 테이블과 뷰(2020.06.10) (0) 2020.06.10 데이터베이스 조인 조건 반복 동적(2020.06.10) (0) 2020.06.10 데이터베이스 Transact-SQL 기본, 고급(2020.06.09) (0) 2020.06.09 데이터베이스 Transact-SQL 기본 (2020.06.08) (0) 2020.06.08