-
데이터베이스 Transact-SQL 기본 (2020.06.08)데이터베이스 2020. 6. 8. 14:51
T_SQL의 분류
*****DML (Data Manipulation Language)
데이터 조작 언어 (선택 삽입, 수정, 삭제) SELECT INSERT UPDATE DELETE = CRUD
REQUEST CREATE UPDATE DELETE
Specification
화면 C R U D 회원 O O O O 구매 O O O 테이블이 정의되어 있어야 사용 가능
DDL (Data Definition Language)
데이터 정의 언어 (데이터베이스, 테이블, 뷰 ,인덱스)
개체를 생성/삭제 변경 CREATE DROP ALTER
DCL (Data Control Language)
데이터 제어 언어 서버 관리자
GRANT, REVOKE, DENY
SELECT 문
[WITH <common_table_expression>]
SELECT select_list [INTO new_table]
[FROM table_source]
[WHERE search_condition]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expression [ ASC | DESC ] ]
주석 : '--' 또는 /* ~~~~ */
SELECT 열목록
FROM 테이블
WHERE 조건


위치한 DB가 master라도 마치 C#의 네임스페이스를 사용하듯이, ShopDB.dbo.memberTBL이라는 정확한 위치를 입력하데이터베이스에 접근한다.
EXEC sp_helpdb; exec는 저장 프로시져

아이디와 아이디가 묶여있어야 누가 뭘 샀는지 알 수 있다. 다른 테이블의 기본키가 와서 쓰이는 키가 외래키라고 한다. 구매를 누가 했는지 왼쪽에서는 아이디가 기본키고 기본키가 참조하는 오른쪽의 키가 외래키이다.

데이터베이스 생성 및 위의 표와 같이 테이블 생성 buyTBL에서 FOREIGN KEY REFERENCES userTBL(userID)는 buytable의 userID는 userTBL의 userID를 참조하는 외래키이다.
테이블 생성 완료

데이터베이스 다이어그램 우클릭 -> 새로만들기 -> 테이블 두개 선택 -> 생성
두개 사이의 관계를 다이어그램으로 나타낸다. 둘이 연결되어 있는 이유는 FOREIGN KEY REFERENCES userTBL(userID) 때문이다.
INSERT 문 사용
더보기INSERT INTO userTBL VALUES('LSG', '이승기',1987, '서울', '011', '1111111', 182, '2008-8-8');
INSERT INTO userTBL VALUES('KBS', '김범수',1979, '경남', '011', '2222222', 173, '2012-4-4');
INSERT INTO userTBL VALUES('KKH', '김경호',1971, '전남', '019', '3333333', 177, '2007-7-7');
INSERT INTO userTBL VALUES('JYP', '조용필',1950, '경기', '011', '4444444', 166, '2009-4-4');
INSERT INTO userTBL VALUES('SSK', '성시경',1979, '서울', NULL, NULL, 176, '2013-12-12');
INSERT INTO userTBL VALUES('LJB', '임재범',1963, '서울', '016', '6666666', 182, '2009-9-9');
INSERT INTO userTBL VALUES('YJS', '윤종신',1969, '경남', NULL, NULL, 170, '2005-5-5');
INSERT INTO userTBL VALUES('EJW', '은지원',1972, '경북', '011', '8888888', 174, '2014-3-3');
INSERT INTO userTBL VALUES('JKW', '조관우',1965, '경기', '018', '9999999', 172, '2010-10-10');
INSERT INTO userTBL VALUES('BBK', '바비킴',1973, '서울', '010', '0000000', 176, '2013-5-5');
GO
--INSERT INTO userTBL (userID,name,birthday, addr)VALUES('SMG','성명건',1976,'부산')
--INSERT INTO userTBL (userID,addr,birthday,name)VALUES('SMG','부산','성명건',1976)
--순서는 중요치 않다. 앞에 명시할 경우 앞에 속성 따라간다.
INSERT INTO buyTBL VALUES('KBS','운동화',NULL,30,2);
INSERT INTO buyTBL VALUES('KBS','노트북','전자',1000,1);
INSERT INTO buyTBL VALUES('JYP','모니터','전자',200,1);
INSERT INTO buyTBL VALUES('BBK','모니터','전자',200,5);
INSERT INTO buyTBL VALUES('KBS','청바지','의류',50,3);
INSERT INTO buyTBL VALUES('BBK','메모리','전자',80,10);
INSERT INTO buyTBL VALUES('SSK','책','서적',15,5);
INSERT INTO buyTBL VALUES('EJW','책','서적',15,2);
INSERT INTO buyTBL VALUES('EJW','청바지','의류',50,1);
INSERT INTO buyTBL VALUES('BBK','운동화',NULL,30,2);
INSERT INTO buyTBL VALUES('EJW','책','서적',15,1);
INSERT INTO buyTBL VALUES('BBK','운동화',NULL,30,2);
GO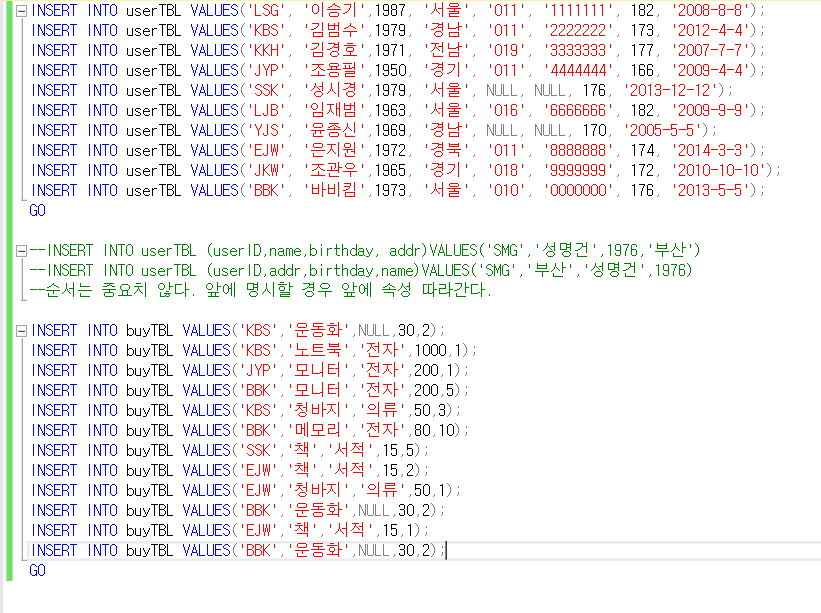
다시 타이핑하기 귀찮으니 파일을 찾던가 저장 잘해놓는다.
WHERE 조건절

1. userTBL에서 USERID 중에 'JYP'인 로우를 출력하라.
2. userTBL에서 USERID 중이 'L'로 시작하는 로우를 출력하라,
3. userTBL에서 name이 '김경호'인 로우를 출력하라
4. userTBL에서 mobile1이 '010' 인 로우를 출력하라
5. userTBL에서 birthday가 1970보다 큰 로우를 출력하라.

5. userTBL에서 birthday 가 1970 이상이고 height가 177 이상인 사람을 출력하라
6. userTBL에서 birthday 가 1970 이상이거나 height가 182 이상인 사람을 출력하라.

7. userTBL에서 height가 180이상 height가 183 이하인 사람을 출력하라.
BETWEEN을 사용해서 똑같은 조건을 출력한다.


8. userTBL에서 addr이 경남이거나 전남이거나 경북인 사람 중에서 이름과 주소만 출력하라.
밑의 두 줄 모두 같은 결과를 출력하나 IN 을 사용해서 간략하게 표현했다.

9. 이름이 김으로 시작하는 로우를 출력하라
10. 이름이 앞글자 상관없이 종신으로 끝나는 세글자를 가진 로우를 출력하라.

서브쿼리

하지만 서브쿼리가 여러개의 값을 반환한다면?

해결
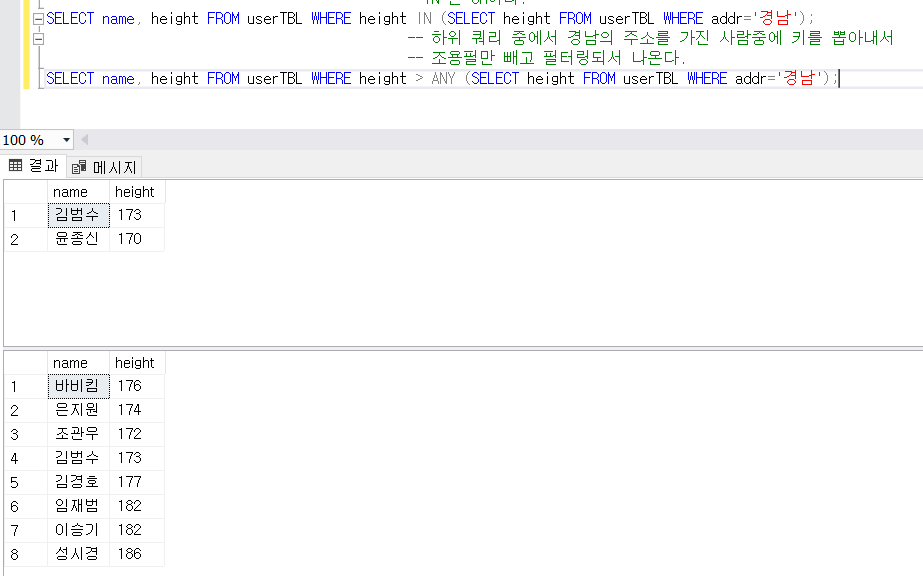
우리가 데이터를 INSERT할때의 순서가 아니라 기본적으로 기본키의 오름차순으로 나온다.

내림차순으로 바꿔보자. 내림차순 DESC, 오름차순 ASC

가격을 기준으로 정리하면 보기 편하다.


1차로 가격으로 내림차순하고 그다음 같은가격 안에서 이름을 알파벳 순으로 정리한다,
쇼핑몰사이트에서 가격을 오름차순으로 검색했을 때 ASC
반대는 DESC
등록일 DESC는 제일 빠른 일부터,
리뷰는 리뷰카운트가 많은 순대로
다 ORDERBY 쓴다.
TISTINCT
아래 예제에서 같은 지역을 제외하고 보고 싶을 때, SELECT 뒤에 DISTINCT 를 붙인다.

TOP(5)

가격을 기준으로 상위 5개의 항목만 출력한다.
SELECT INTO
SELECT 복사할열 INTO 새로운테이블 FROM 기존테이블
buyTBL에서 userID 와 prodName을 buyTBL_new를 복사한다. 이때 키 값과 인덱스는 복사하지 않는다.


보통 프로그램 상에서 은행에서 오늘 2020년 6월 7일 하루 금융업무 다보고나면 다름 백업 테이블로 옮길 때 사용한다. 그리고 복사가 끝난 원래 데이터는 날려버린다.
GROUP BY
같은 것들끼리 묶을 때 쓴다. GROUP BY 한건 WHERE 절에 적지 못한다.


위의 오류는 이렇게 하면 해결된다. 하지만 sum(amount)에는 열이름이 없음이 나온다. 필드의 값이 아닌 합산된 결과를 도출해 준 것 뿐이기 때문에, 뭔지 구분이 안가고 subquery할 때 이 값을 써야되는데 쓸 방법이 없다. 따라서
AS 문을 사용해서 이름을 준다.

열이름이 바뀐 것을 알 수 있다.
함수명 설명 AVG() 평균을 구한다. MIN() 최소값을 구한다. MAX() 최대값을 구한다. COUNT() 행의 개수를 센다. COUNT_BIG() 개수를 센다. 단 결과값이 bigint 형이다. STDEV() 표준편차를 구한다. VAR() 분산을 구한다. 이렇게 하면 GROUP BY를 사용하지 않아도 된다. 그 이유는 그냥 갯수의 평균만 구하면 되기 때문이다.

하지만 사용자가 들어간다면


GROUP BY 에 있으면 앞에 SELECT에도 똑같은 열이름이 들어있어야한다.
************************************************* 가장 키가 큰 사람과 작은 사람을 출력하기

그루핑을 하기 위한 필드는 반드시 그룹바이에 들어가야 한다. 그게 기본 문법이다.
핸드폰이 없는 사용자 출력

총 구매액 구하기

총 구매액이 1000원 이상 되는 사람 구하기


필요한 수를 뽑아내는게 MIN MAX COUNT 등등 딸랑 하나만 썼을 때는 그룹바이가 필요없는데 원하는 그루핑을 하려면 GROUP BY 가 들어가야 한다. WHERE은 필드값에 대한 조건, 필드 값 등등 넣을 수 있고, 집계함수들은 HAVING에다가 넣는다.
7시간반을 수업했는데 기억나느게 없다.
'데이터베이스' 카테고리의 다른 글
데이터베이스 테이블과 뷰(2020.06.10) (0) 2020.06.10 데이터베이스 조인 조건 반복 동적(2020.06.10) (0) 2020.06.10 데이터베이스 Transact-SQL 기본, 고급(2020.06.09) (0) 2020.06.09 데이터베이스 전체 운영 실습, 툴과 유틸리티 (2020.06.08) (0) 2020.06.08 데이터베이스 SQL 서버 설치 (0) 2020.06.05